Introduction
A web browser for foreign languages: LinguaBrowse
LinguaBrowse is an iOS app for reading native-level foreign-language texts on the internet. It allows users to look up any unknown word on a web-page in a popup dictionary, simply by tapping on it; so users don’t have to wrestle with any text selection boxes nor constantly switch out to a dictionary app.
In this post, I’ll detail all the language processing that goes on under the hood to facilitate this multilingual tap-to-define functionality.
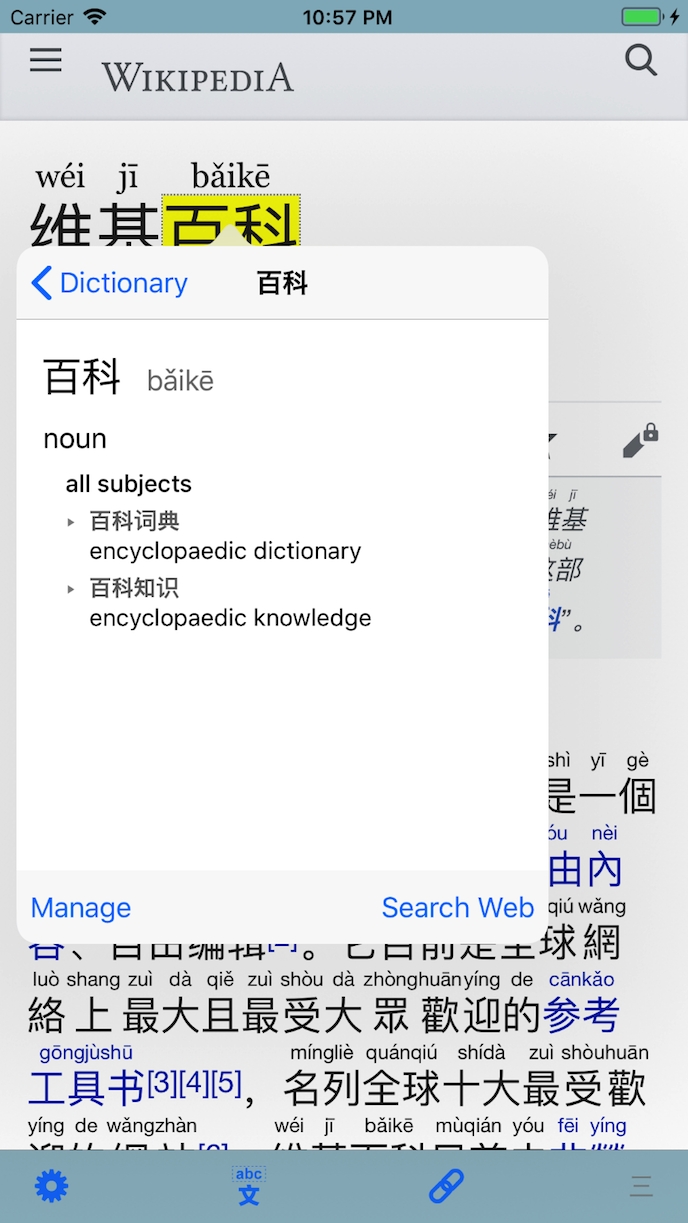
NLP tools used by LinguaBrowse
The tap-to-define functionality employs two of Apple’s Natural Language Processing tools:
-
CFStringTokenizer, which I use to initially process the text of a page into tokens (that the user can tap upon to prompt a dictionary lookup) and for adding transcriptions to non-Latin scripts (e.g. adding pīnyīn to Mandarin).
-
NSLinguisticTagger, to subsequently convert any tapped token into dictionary form (if necessary) before lookup.
-
CFStringTransform, to convert traditional Chinese characters into Simplified form (because the iOS Chinese <-> English system dictionary expects Simplified Chinese). In an old part of my codebase, I’m also using it to transliterate Thai for some reason.
I substitute CFStringTokenizer and NSLinguisticTagger with MeCab to provide lemmatisation support for Japanese and Korean. This is the tool that Apple have used since at least Mac OS 10.5 for Japanese tokenising[1][2], and I have heard it’s even the exact tokenizer used in CFStringTokenizer for Japanese. Whether the older NSLinguisticTagger (‘NS’ indicating NeXTSTEP, and ‘CF’ indicating Core Foundation) uses it too is another question altogether.
What is CFStringTokenizer useful for?
CFStringTokenizer makes sense of texts: it can figure out the predominant language, add Latin transcriptions to words, and split up texts up into smaller units, such as paragraphs, sentences, or words (this is a godsend for languages without spaces). In LinguaBrowse, I use it just for tokenising texts into arrays of words and adding transcriptions.
For Mandarin, which lacks any inflections, every token output by CFStringTokenizer will map to a dictionary-form word, and can thus be looked up in a dictionary as-is. However, most other languages have grammatical obstacles such as inflections that would cause lookup of the word as-is to fail (or return poor results). This is where NSLinguisticTagger comes in.
What is NSLinguisticTagger useful for?
NSLinguisticTagger has a lot of overlapping functionality with CFStringTokenizer: again, it can tokenise texts into smaller units, identify the dominant language for said units, but it can also do so much more. It can also identify the dominant script (such as Cyrillic or Simplified Chinese) of a unit, identify part-of-speech of a word – including classifying by sub-types, as in named entity recognition – and even identify the lemma (dictionary form) of a word.
As of iOS 11, it’s multi-threaded, it can tokenise all iOS/macOS system languages and identify 52 different languages – however, only eight languages are supported for lemmatisation, part-of-speech identification, and named entity recognition: English, French, Italian, German, Spanish, Portuguese, Russian, and Turkish.
Isn’t CFStringTokenizer redundant?
If NSLinguisticTagger can do tokenising, why introduce NSLinguisticTagger at all?
-
CFStringTokenizer produces more word-sized tokens (see the sections to come on compound nouns and contractions)
-
Unless things have changed with the aforementioned iOS 11 optimisations, CFStringTokenizer is historically orders of magnitude faster at tokenising the same given length of string (although may perform comparably for small strings), and its tokenising time scales far better with input string length.
Thus, I decided to leave the whole-page text tokenising to CFStringTokeniser, and everything else to NSLinguisticTagger!
With NSLinguisticTagger, we can support those eight extra languages by allowing users to look up words by their dictionary forms.
Aiding dictionary lookup with NLP
Introduction
I’d like to highlight a few of the troublesome grammatical features posing problems to dictionary lookup that have required me to call upon a mixture of NLP tools to surmount:
-
compound nouns (examples from English, German, and Japanese)
-
inflected words (examples from English)
-
contractions (examples from French, English, Italian, and – as a bonus – Japanese and Chinese)
1. Compound nouns
What are compound nouns?
Compound nouns are nouns made by combining together multiple words. In English, there are many ways to create them, and they needn’t even contain any nouns. For example:
-
‘bath’ + ‘room’ = ‘bathroom’ (noun + noun)
-
‘small’ + ‘talk’ = ‘small talk’ (adjective + noun)
-
‘hair’ + ‘cut’ = ‘haircut’ (noun + verb)
-
‘dry’ + ‘cleaning’ = ‘dry cleaning’ (adjective + verb)
-
‘draw’ + ‘back’ = ‘drawback’ (verb + preposition)
How should they be processed to aid dictionary lookup?
I’m going to classify compound nouns into two types: those delimited by spaces (e.g. ‘dry cleaning’), and non-delimited ones (e.g. ‘bathroom’). Space-delimited ones are resolved by CFStringTokenizer as multiple tokens, while non-delimited ones are resolved as a single token.
For space-delimited compound nouns, looking up each consituent part is often enough to deduce the meaning: For example, the meaning of ‘deputy head’ is easy to infer from its parts. However, just as often, the meanings of the constituent parts are unhelpful (e.g. for words like ‘vice principal’). In these cases, LinguaBrowse’s online dictionaries provide linkes to entries for any compound nouns deriving from a looked-up word.
For undelimited compound nouns, at least in English, it is best to look up the whole word as-is. For example, the word ‘greenhouse’ can only be understood as its whole. However, an ability to define the constituent parts will often be of help to learners. No clearer is this fact than in German, where compound nouns can grow as long as ‘Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz’ (meaning the “law for the delegation of monitoring beef labelling”)! Thus, we can handle them as follows:

In this example, the user has the option of looking up the whole word as-is, or by its sub parts, which are each in dictionary form where available.
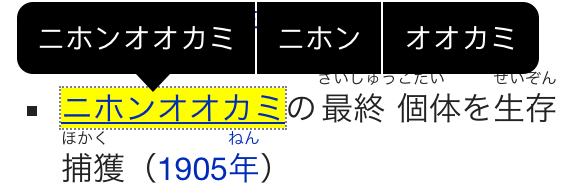
I also use NSLinguisticTagger in Japanese for some katakana compound nouns that MeCab fails to split properly (perhaps it uses a different dictionary to NSLinguisticTagger/CFStringTokenizer):
2. Inflected words
What are inflected words?
An inflected word is one that may change its form to express a grammatical function/attribute such as tense, subject, mood, person, number, case, or gender. Examples common to many languages are:
-
conjugated verbs
-
inflected adjectives
-
plural forms of nouns
How should they be processed to aid dictionary lookup?
For most cases, the simple answer is to just return the lemma given by NSLinguisticTagger. And if NSLinguisticTagger doesn’t support lemmatisation for the given language, then we’ll just have to look up the word as-is and hope the dictionary can give us a best-effort result.
However, a radical option does exist: Bundle your own extra lemmatisers into the app. I’ve done so for Japanese and Korean, with MeCab. While it was traditionally developed for Japanese tokenisation, I found a project to adapt MeCab for Korean usage, I incorporated the code into my own fork of an iOS wrapper for MeCab. I have lofty dreams of incorporating lemmatisers for every language under the sun, but for now, it’s a stretch goal.
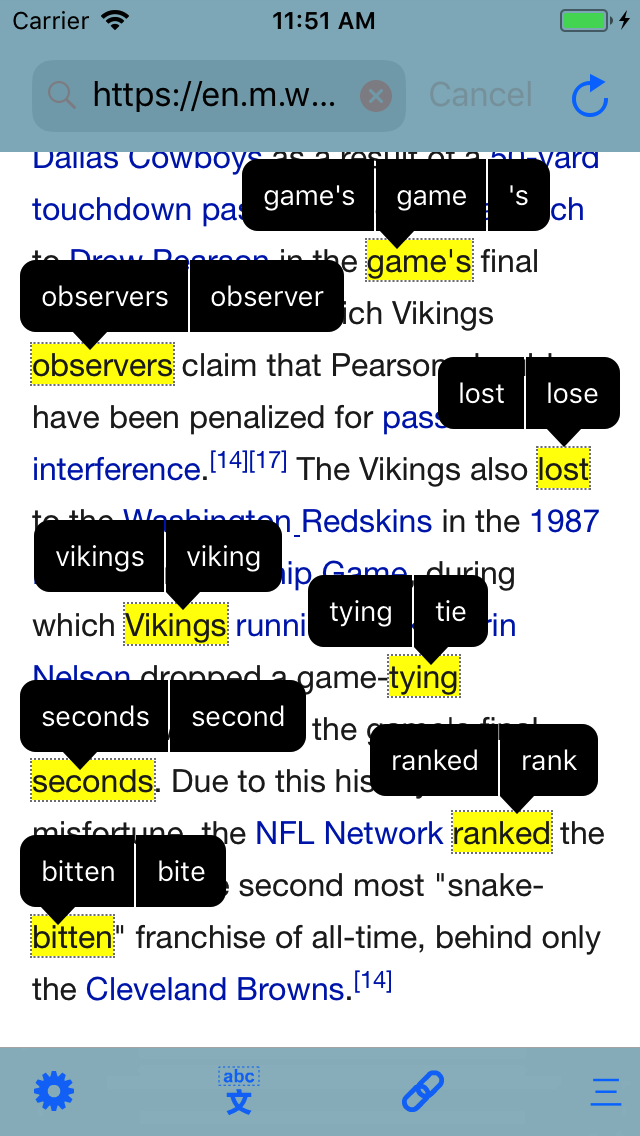
So now, when tapping on an inflected word, users are given the opportunity to look it up either as-is, or by its lemma (whenever NSLinguisticTagger can determine it). A plethora of examples from English, all superimposed into one image:
3. Contractions
What is a contraction?
A contraction is when a word is shortened from its original form, usually mirroring how the word is spoken in practice. English is chock-full of these:
- “shoulda” -> “should have”
- “gotta” -> “got to”
- “it’s” -> “it is”
- “let’s” -> “let us”
- “they’re” -> “they are”
- “y’all” -> “you all”
- “fish ‘n’ chips” -> “fish and chips”
The definite articles of French and Italian also induce a lot of this:
- French: “l’occasion” -> “la occasion”
- French: “l’aspect” -> “le aspect”
- Italian: “l’occasione” -> “la occasione”
- Italian: “l’aspetto” -> “lo aspetto”
A significant problem to learners here is that this obscures the gender of the noun, preventing one from learning how to use the word in other contexts.
I’m focusing just on contractions in languages with Latin scripts here, but I’ll touch upon those of non-Latin script languages at the end.
How should they be processed to aid dictionary lookup?
While most English contractions will be listed in a dictionary as-is (due to them being an accepted form of the word), contractions based on definite articles, such as those common in Italian and French, will often have the definite articles omitted. Instead, the dictionaries may just categorise the word as ‘masculine’ or ‘feminine’. So only a forgiving dictionary would facilitate lookup of such words.
Thanks to NSLinguisticTagger, we can now separate definite-article contractions into their parts, allowing search by part of the word. Regrettably, NSLinguisticTagger does not lemmatise “l’” back to its full form ‘le’ or ‘la’ to show gender, but it sure would be nice to add by some other means in future.

What about languages with non-Latin scripts?
Contractions look rather different in languages with non-Latin scripts, and pose different problems to text processing. I’ll introduce contractions in two different agglutinative languages, Japanese and Chinese, then comment on how they should be both handled.
Japanese
Japanese contractions are pretty commonplace due to Japanese having a phonetic alphabet.
-
やっぱり -> やっぱ
-
何だと言って/何で有っても -> 何だって
-
ありがとうございます -> あざす
-
Many nouns, as listed in this utterly uncited article
Chinese
Chinese contractions are harder to come by because, as far as I gather, they exist only within slang. Lacking a dedicated phonetic alphabet (apart from Bopomofo, which is not used stand-alone), Chinese does not lend itself well to phonetic contractions. Nonetheless, they do exist.
These examples are predominantly from Taiwan Mandarin, and may be restricted to net-speak:
- 知道 (zhīdào) -> 造 (zào)
-
什么时候 (shénme shíhòu) -> 神兽 (shénshòu)
-
我会 (wǒ huì) -> 伟 (wěi)
-
今天 (jīntiān) -> 间 (jiān)
These ones are perhaps historical:
How should they be processed to aid dictionary lookup?
In both these languages’ cases, handling of the contractions requires both a well-trained tokeniser (to correctly identify the word boundary and ideally produce the dictionary form) and a good dictionary (to correctly interpret the word when looked up); there’s not much more that can be done on the developer’s end if relying upon just CFStringTokenizer and NSLinguisticTagger. At best, I could try to upgrade my MeCab’s Japanese dictionary from NAIST’s JDic to NINJAL’s UniDic (which is trained on a monstrously larger corpus[1][2]).
Realistically, though, I think we’ll be able to live without special handling for such contractions! There will always be cases where the user will have to pick up slack for automatic study tools, and this is one of the less criminal ones.
Wrap-up
Hopefully this real-world application has given some clarity about the overlapping use cases of CFStringTokenizer and NSLinguisticTagger, and exposed a few intriguing aspects of different languages.
If you liked this dev note, you can get notified of future ones (and progress updates on LinguaBrowse) at:
You can also try out the LinguaBrowse app via: